RetinanetのFocal Lossに関する覚書 "Focal Loss for Dense Object Detection"
物体検出における損失 Focal Lossに関する覚え書き。
Focal Loss for Dense Object Detection @ ICCV2017
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollar @ Facebook AI Research
式、図、表はarXiv論文からの引用。
動作はGitHubのkeras-retinanet。
1. 概要
CNNを用いた物体検出アルゴリズムは下記2つに大分類される
One-Stage(Shot) Detector系・・・YOLO, SSD, Feature Pyramid Networks(FPN)など
Two-Stage(Shot) Detector系・・・Faster R-CNN(Mask R-CNN)など
物体検出、セマンティックセグメンテーションにおけるバックボーンアーキテクチャの基本アイデアは同一。
Region ProposalされるEasy Example(Easy Negative) - Hard Example(Hard Negative)間のサンプル数不均衡が精度に影響を与えているとの考えの元、新たな損失 Focal Loss を定義する。
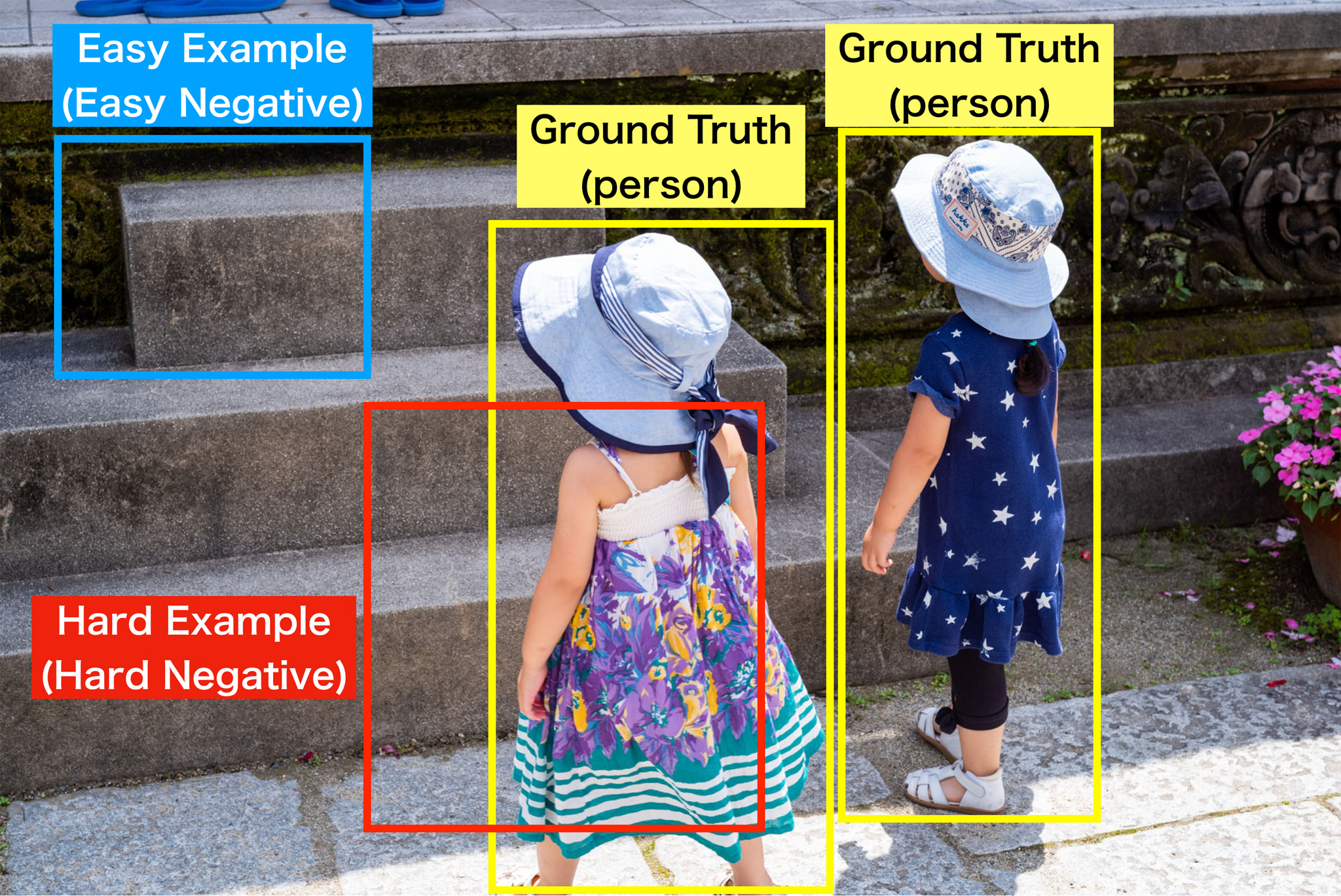
Easy-Hard Exampleの例。詳細はHard Negative Mining, Hard Example Miningなどで調べるか、初代R-CNNの論文を熟読すべし。
2.Cross Entropy
物体 or 背景の2値分類を考えた時、クロスエントロピー(CE)は式(1)で表現される。
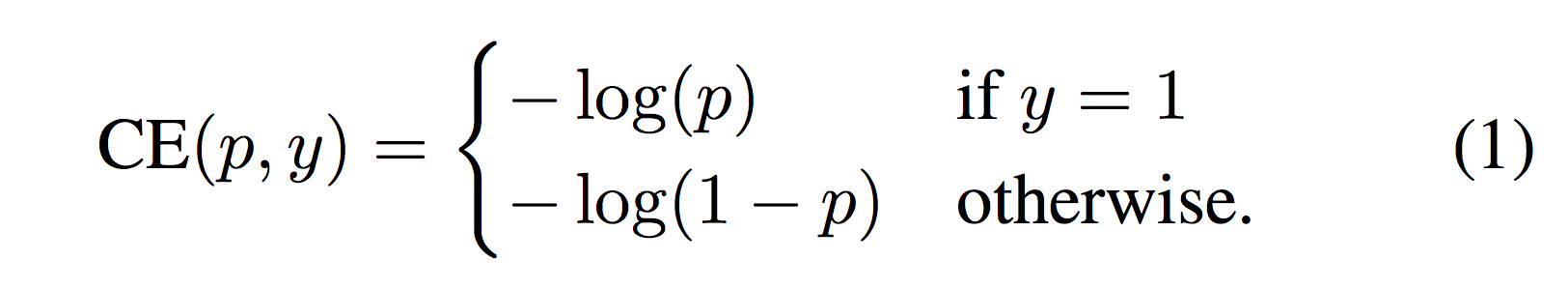
pはprobabilityで確率のこと。下記(2)を参照。
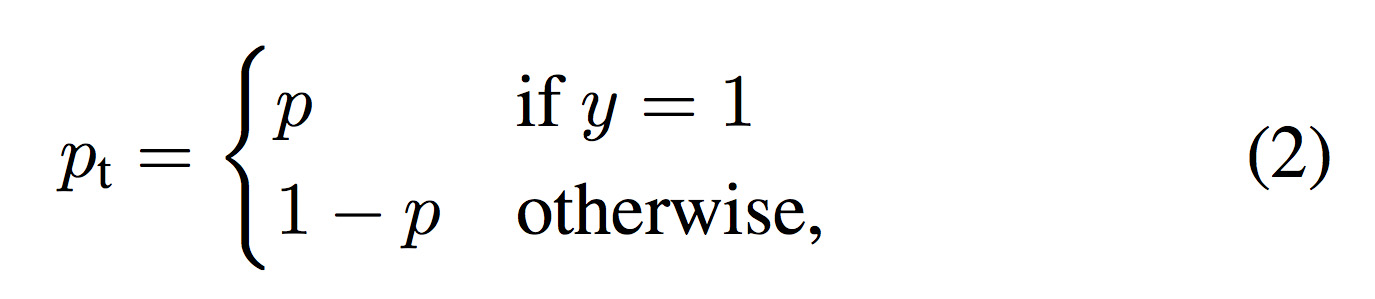
3.Focal Loss
新たにFocal Loss(FL)を式(4)で定義する。
γは任意に設定するハイパーパラメータ。
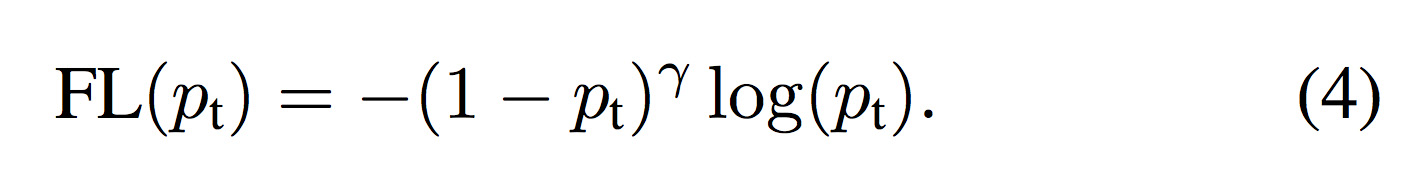
前述のクロスエントロピー(CE)とフォーカルロス(FL)を、横軸pとしてプロットすると下図となる。
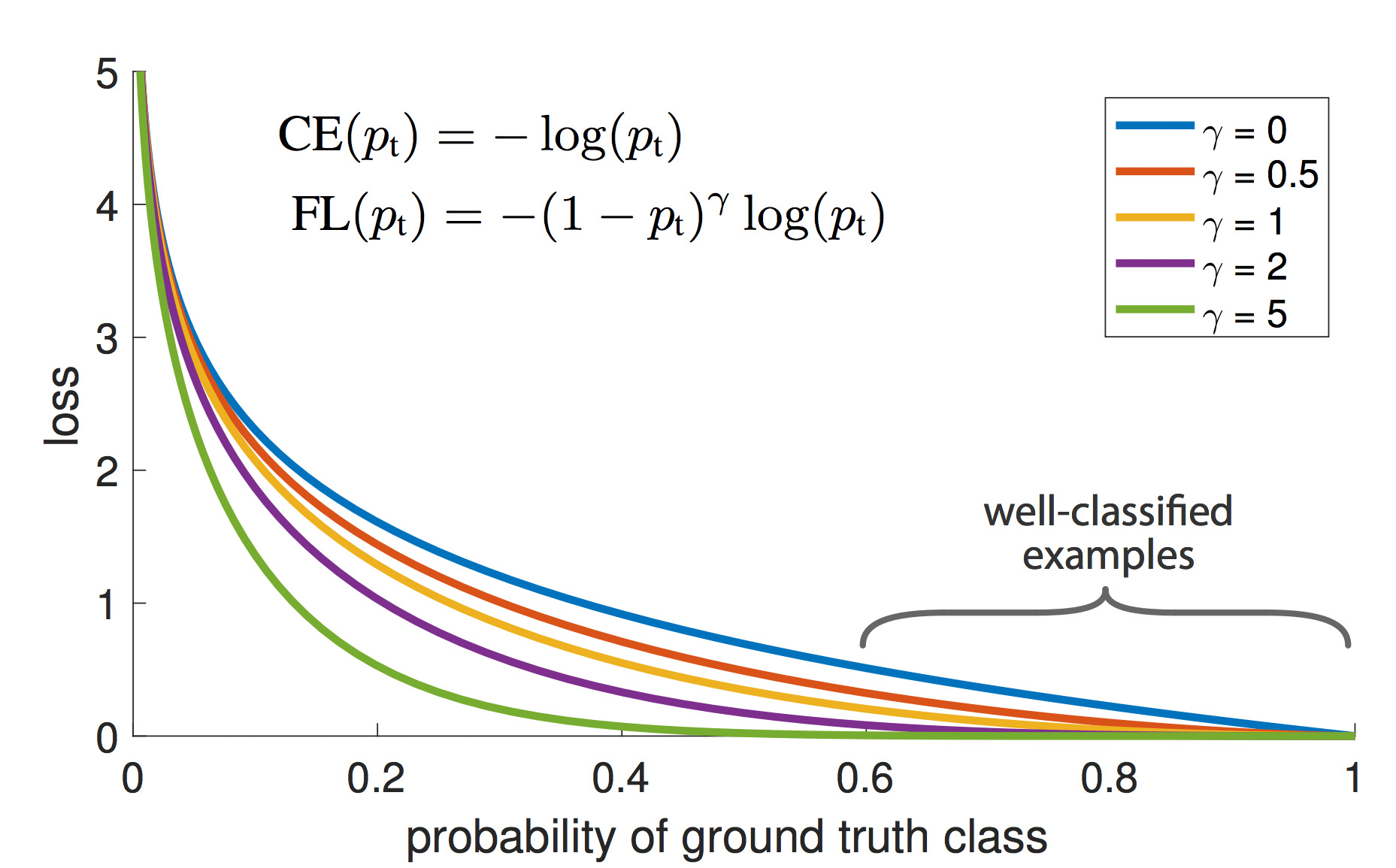
フォーカルロス(FL)がγ=0の場合がクロスエントロピー(CE)となる(0乗されて1となるため)。
上手く分類されたサンプルの損失が低減していく様子が確認出来る。
4.Balanced Cross EntropyのFocal Lossへの拡張
Positive-Negative間の不均衡に対する手法としてバランスドクロスエントロピー(BCE)がある(式(3))。
クロスエントロピー(CE)に重み係数α (0 ≦ α ≦ 1)を掛ける(式(3))。
重み係数αは任意に設定する。
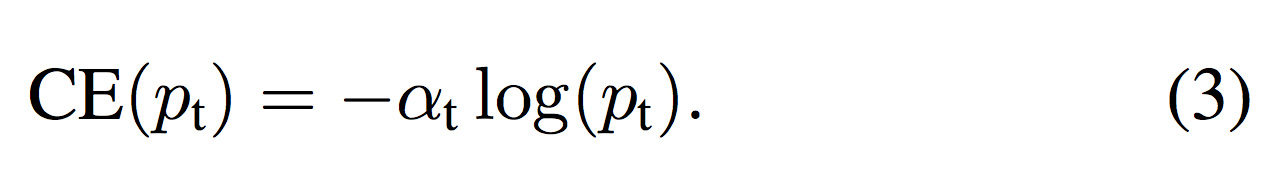
前述した式(4)のフォーカルロス(FL)に重み係数αを掛けると式(5)となる。
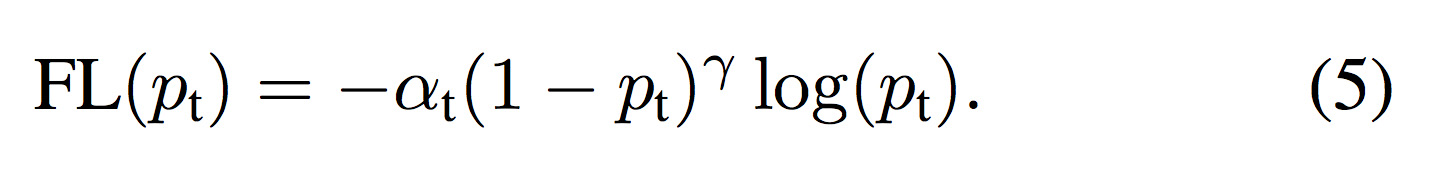
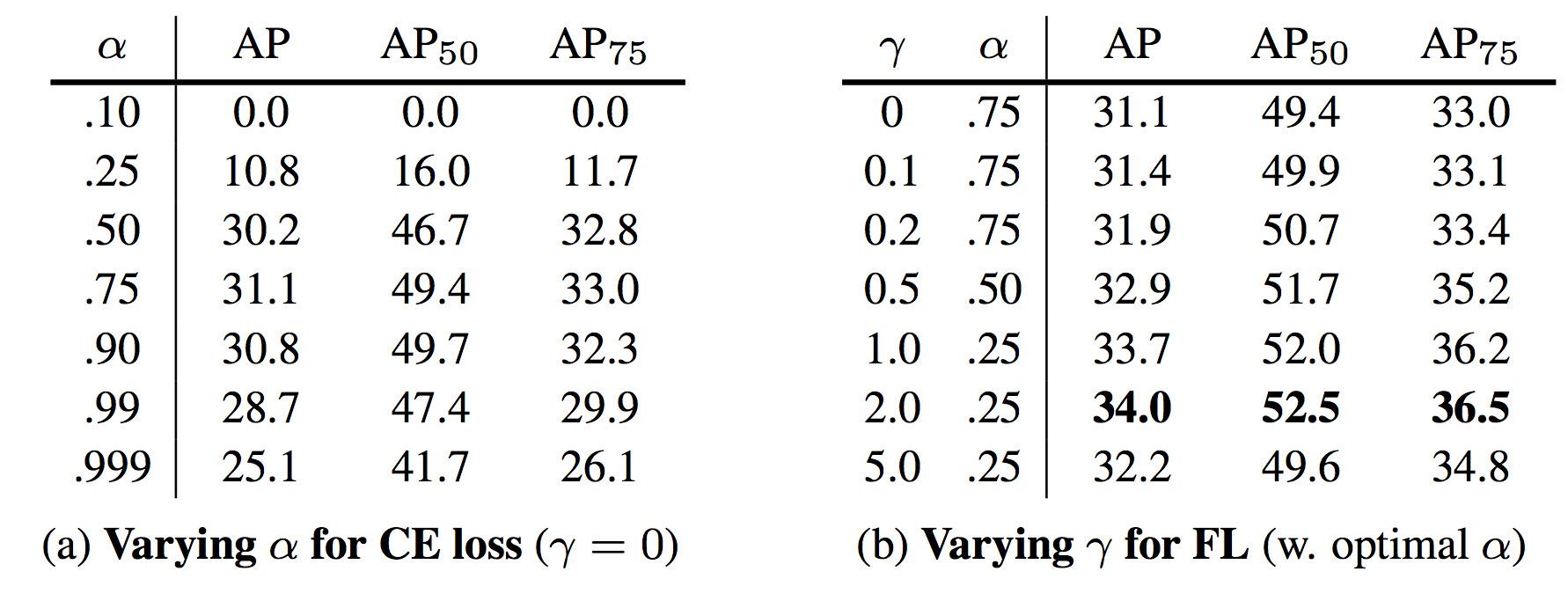
γとα、2種類のハイパーパラメータが出来たため、グリッドサーチした結果が下表。
5.ネットワークアーキテクチャ
論文ではFeature Pyramid Networksに適用されている。
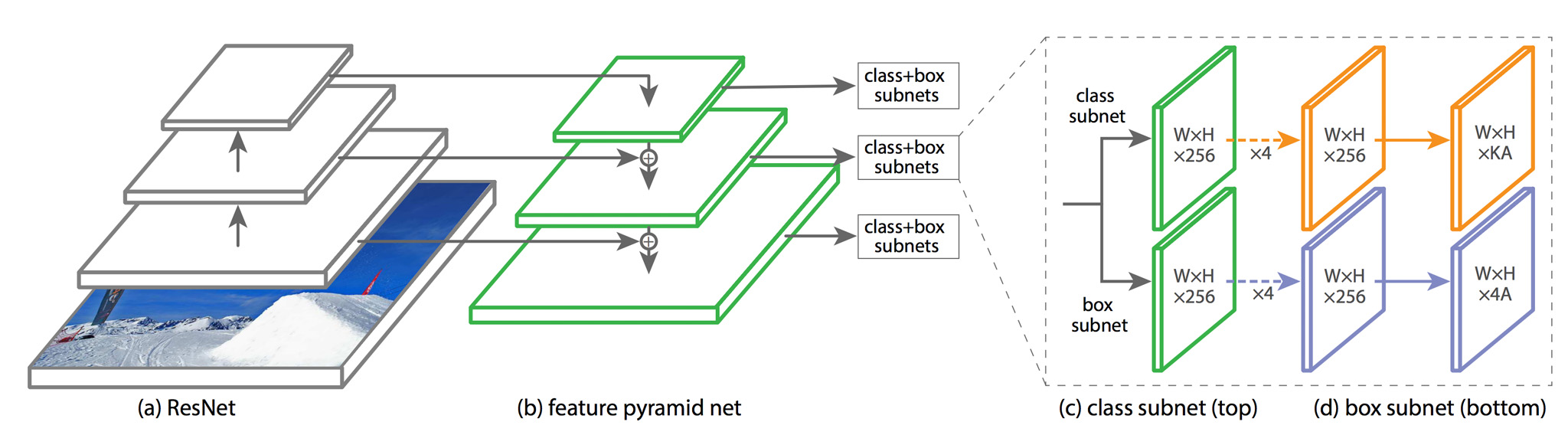
6.所感
・lossの設定は常に付きまとうため、そこに新たな方法が見つかったのは今後の応用と実用に期待が持てる。
・速度 vs 精度のトレードオフだったOne-Shot vs Two-Shotの選択問題も、One-Shotで統一される時代が来るか・・・?
・空間解像度を維持する方法がFPNやU-Netのショートカット回路以外に見つかるのだろうか?
下記画像をkerasでの実装(keras-retinanet)に入力。
・バックボーンはResNet50、学習済みデータセットはCOCO。
・自宅にアノテーション済み自前データセットと超強いGPUが無いため動作させたのみ。
・ハードはMacbook Pro Late 2013、GPUはGeForce GT 750M。

処理時間: 6.34sec / Frame
なかなかにヘビーですね・・・。

・WordPressにLaTeXとかソース貼り付け用のプラグインを入れてないので、入れたほうが楽だったかもと、ここまで書いて思う。
・Qiitaで書いたほうがウケそうなネタなので、Qiitaで書いてまとめる癖をつけるべきか悩む。PVの伸び方次第で考えます。
=========== 追記 ============
せっかくのDense Object Detectionなので、密集してる画像を入れてみた。
どれも処理速度は6.2秒前後

視野内全部が被写界深度に入っているのと、光源も安定しているのでかなり上手く検出出来ている。

藤棚からの影による縞模様にも負けてません。
奥の日傘もアンブレラで分類。

奥の日傘は検出できているものの、手前の日傘は被写界深度から外れているせいか分類できず(閾値弄れば出てくるでしょうが)。